上一篇文章简单介绍了一下nix核心在做些什么,似乎有些空中楼阁。这次我希望能够通过一个具体的包,让你感受一下,为什么nix这个家伙即使在如此离经叛道的情况下,经过二十多年的发展,狂揽一大批忠实用户和开发者。
当然,你需要先安装nix,并开启nix-command以及flakes两个特性,因为篇幅问题,这部分我就不太赘述了,直接参考determinate systems的文档好了。
本文将带你以最快的速度理解nix的flake机制,准备好了吗?
hello nix
在我们之前有关“究极构建系统”的设想中,将构建过程抽象成了一个函数,参数是构建依赖,返回值是构建结果。而nix实质上,就是一个函数式的构建系统,函数nix的一等公民。接收参数,返回结果:
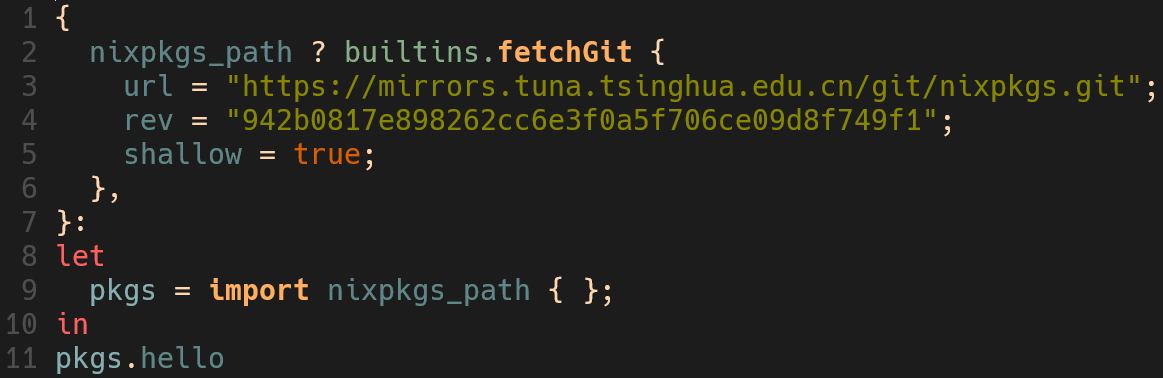
有关上面的代码,你需要理解以下关键内容,更多有关nix语法的介绍可以参考nixos-cn的文档
- 声明了一个函数,以
:为分割,前面为参数,后面为返回值 - 函数接收一个
属性集作为参数,其中只有nixpkgs_path一个属性,当不传递任何参数时,改属性的默认值为fetchGit函数的返回结果 - let … in是一个语法,作用是在一个在有限作用域内声明绑定关系,便于在后面反复使用
- import关键字的作用是从一个路径导入函数,如果路径是一个目录,则导入default.nix
- nixpkgs是一个使用nix语言编写的代码仓库,其中包含了超过12万个包的构建代码
那这个函数做了什么呢?其实什么也没做什么复杂的事情:
- 使用git下载一个目录
- 将目录导入为函数,调用得到pkgs
- 返回pkgs中的hello
这个函数可以说是最简单的构建函数,什么也不做,只把构建参数直接返回。调用函数也很简单:
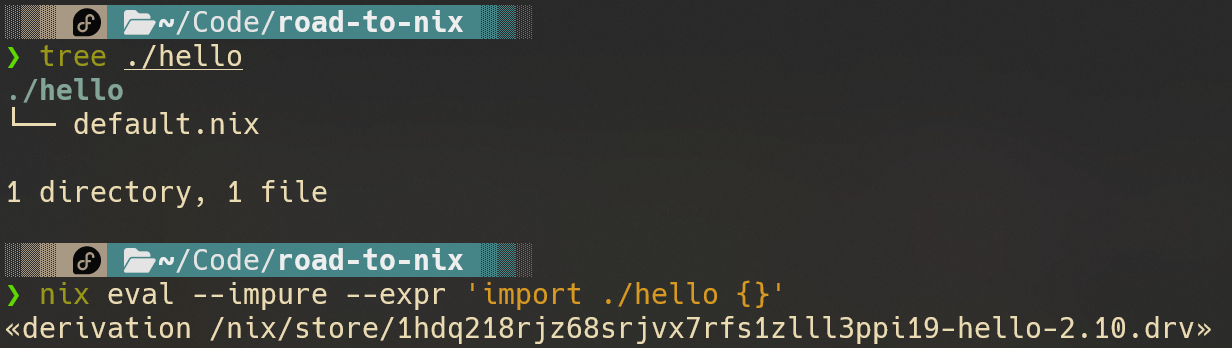
看我们的函数返回了一个什么,.drv?不要怕,如果你读过上一篇【nix之路——究极构建系统】,这个东西就是之前提及的.bld。
使用nix derivation show可以将这个文件转换为json查看:
nixpkgs仓库比较大,下载需要多等待一会儿
当然,直接指定绝对路径也可以:
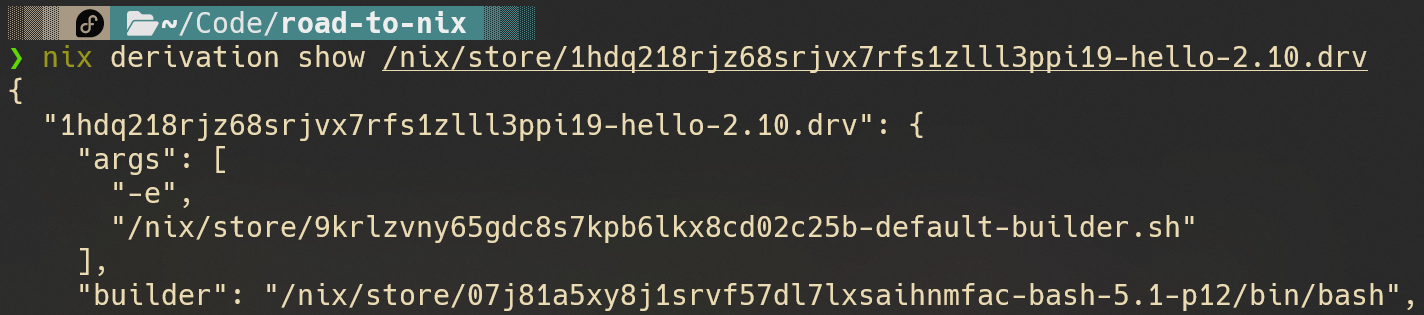
所以说,pkgs.hello实际上对应一个.drv文件,这个文件包含了能够构建这个包的所有信息。那我们如何最终构建他呢?也很简单:
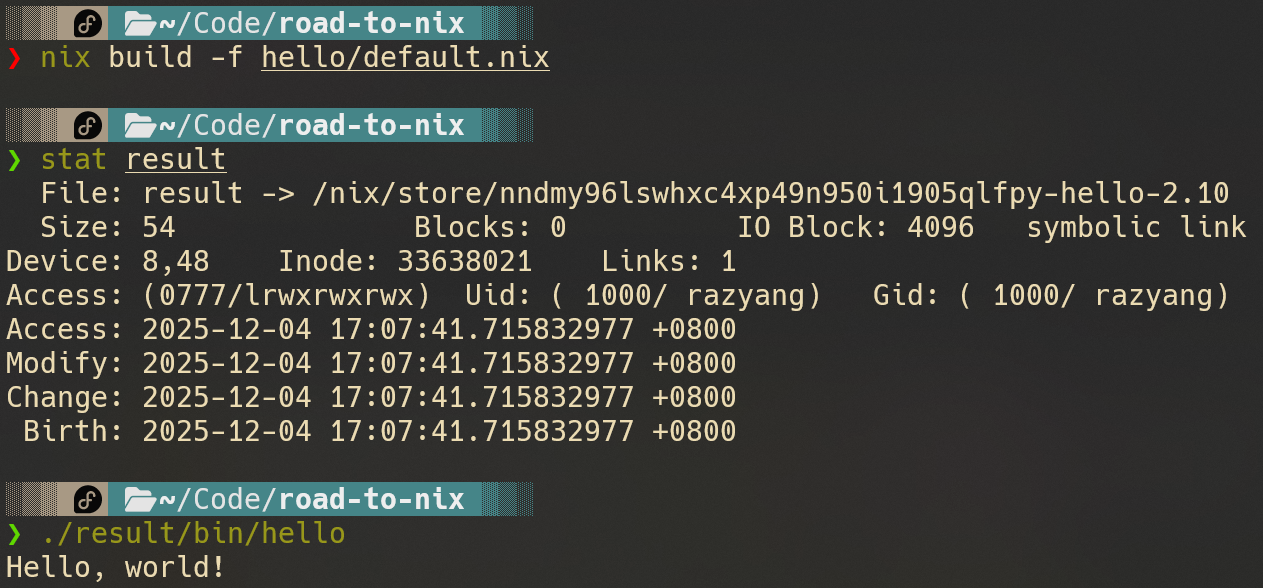
构建完成后,默认会在当前目录建立一个指向产物目录的软连接,让我们可以快速使用
当然,以上只是为了让你更好的理解nix代码和产物的关系,实际上用下面的命令可以构建出一样的结果:

hello flake.nix
也许你发现了,上面我们每次调用default.nix的时候,都要重新下载nixpkgs。而且,函数参数的默认值是一个下载函数,感觉哪里怪怪的。
其实nix提供了一种更好的的,导入外部nix代码依赖的机制,叫做flake,不同于default.nix,当指定一个目录时,flake.nix是默认的入口文件。他的格式也很简单:
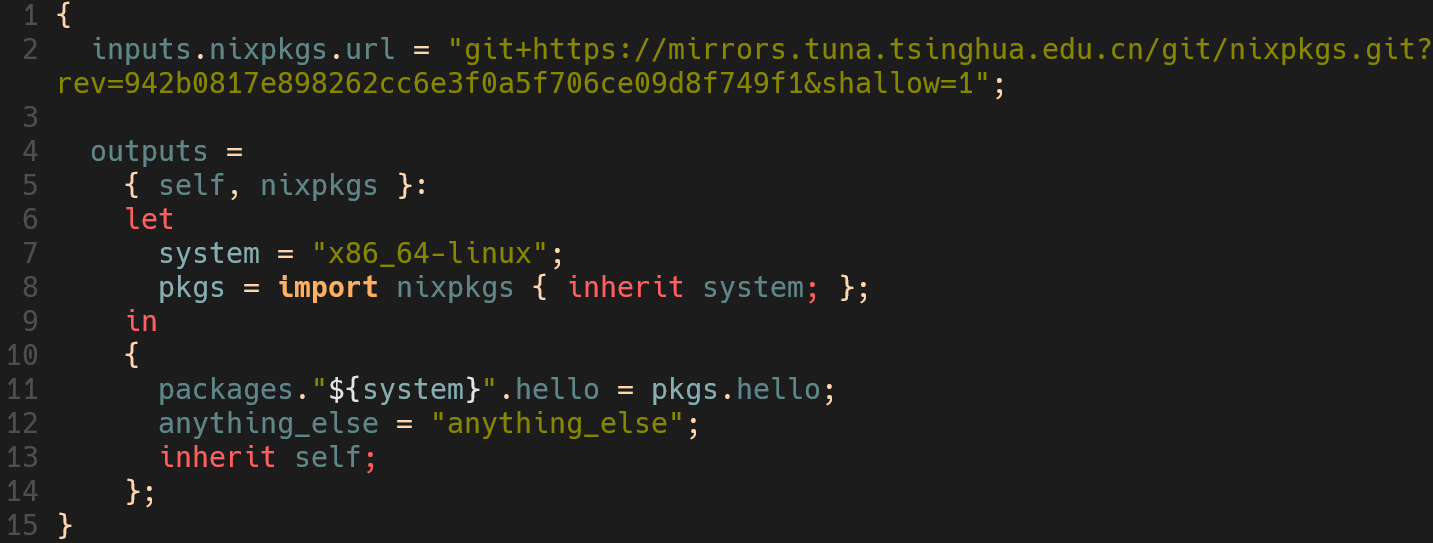
这个文件核心在于inputs以及outputs两部分
inputsinputs声明了需要的外部nix代码仓库地址,地址可以是git仓库、本地路径、压缩包、压缩包下载链接等等outputsoutputs很显然是一个函数,就像上面我们写的default.nix一样,他接收一个属性集作为参数,属性来自inputs中的声明,最后返回一个属性集。
也许你注意到了,不同于我们自己写的default.nix,这里的参数多出了一个self属性,我们可以简单模拟一下flake.nix的执行过程:
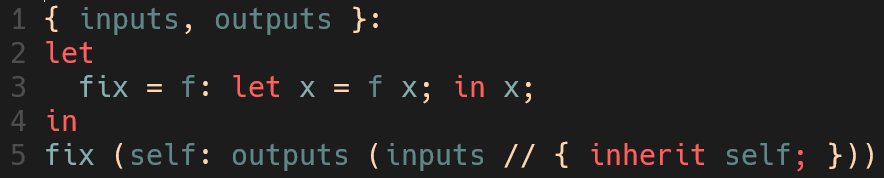 等等等等,发生了什么?这里的
等等等等,发生了什么?这里的fix函数其实是nix语言中的一个常用trick,称为fix point,既然你早晚要面对他,我决定在这里直接告诉你它的存在。
不过,我并不打算在这里过分展开fix point的原理,有关fix point的原理,我看过比较好的介绍是akavel的这篇文章,你可以选择去深入了解一下。
如果你暂时还不想知道fix干了什么,只需要知道它的效果就可以了,在这里我们尝试使用我们的call_flake.nix调用一下flake.nix,看看发生了什么:
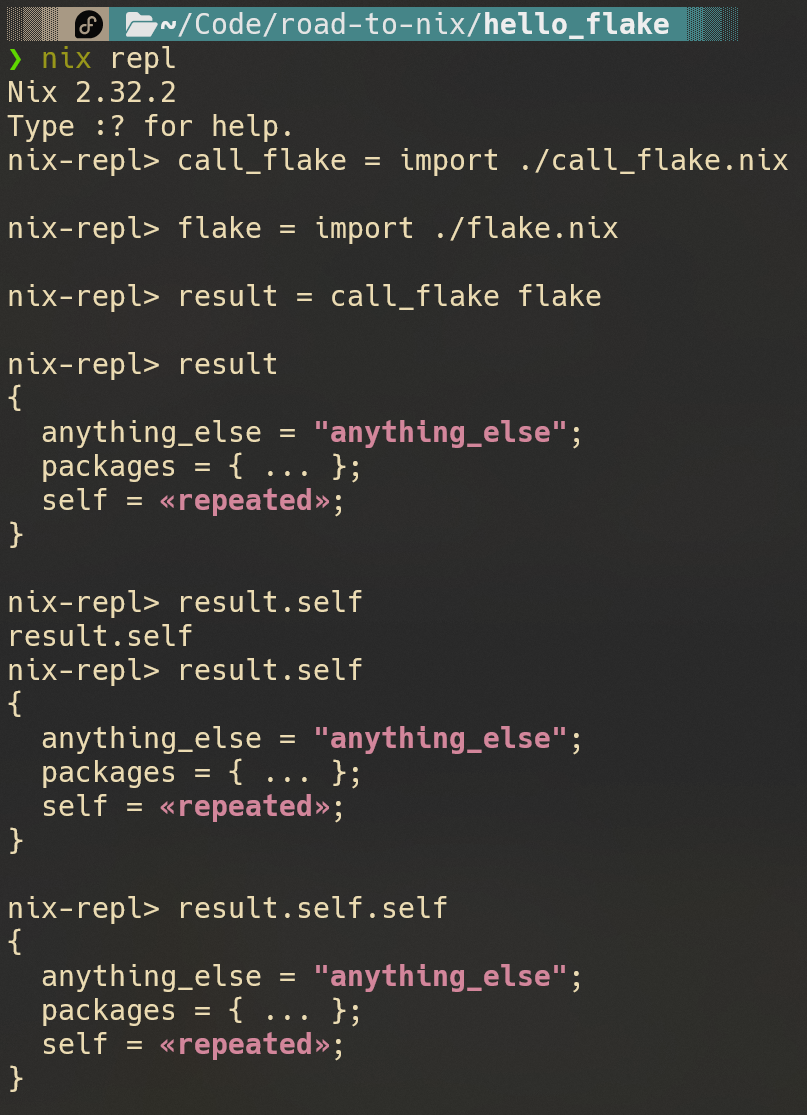
可以看到,如果我们在ouptuts的返回值中导出self,这个self就不断指向返回结果自己。这样可以让你很方便的在outputs的实现中,引用自己对外导出的部分。
好了,小插曲到此为止,还是让我们看一下如何正常操作flake.nix吧:
首先,使用nix flake show可以查看flake中outputs函数的返回结果,但默认支持的类型有限,其他不支持展示的属性只能展示为unknown:
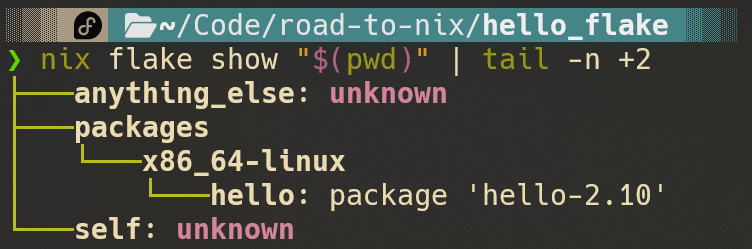
如果你想知道flake的详细返回内容是什么怎么办?你可以调用nix repl,使用:lf来调用flake.nix,获取返回值:
nix_repl_flake
{kind=link}
一个软件包的艺术之旅
我们现在知道flake机制的运作原理,以及如何将gnu hello作为packages.${system}.hello作为flake的返回值返回,那我们都可以对这个包做些什么操作呢?
首先,我们可以使用nix build快速构建一个flake仓库导出的包,构建后默认会在当前目录建立一个指向构建产物的软链接:
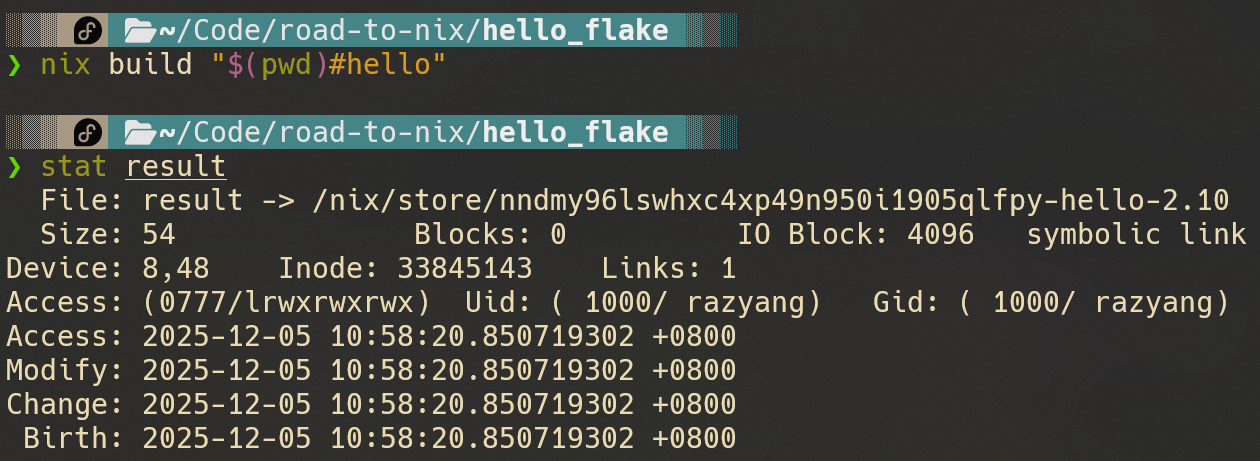 你也可以选择使用
你也可以选择使用nix run直接运行它,运行前他也会检查是否构建过,如果没构建会先构建再执行:
 也可以使用
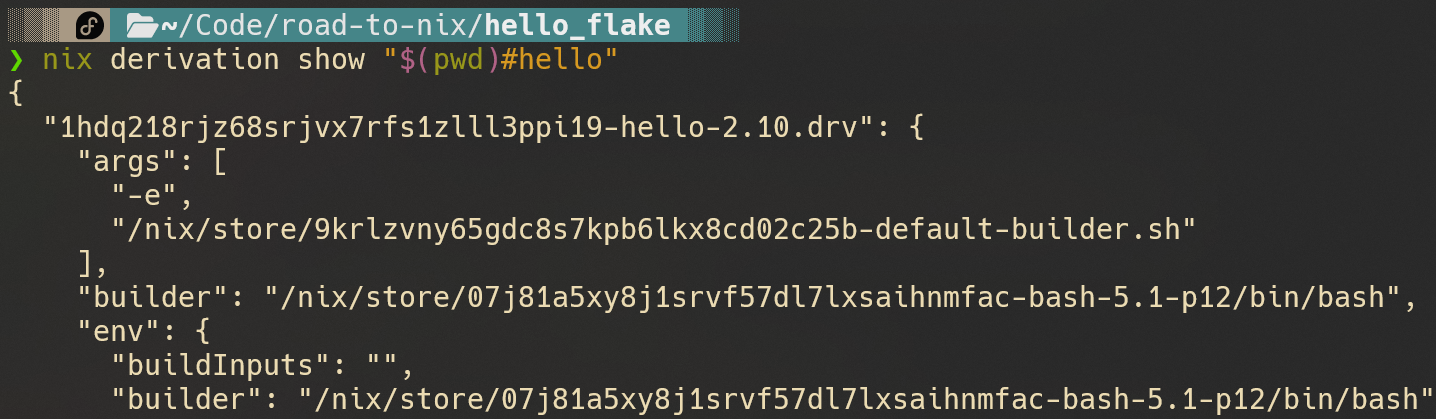
也可以使用nix derivation show查看这个包对应的.drv文件:
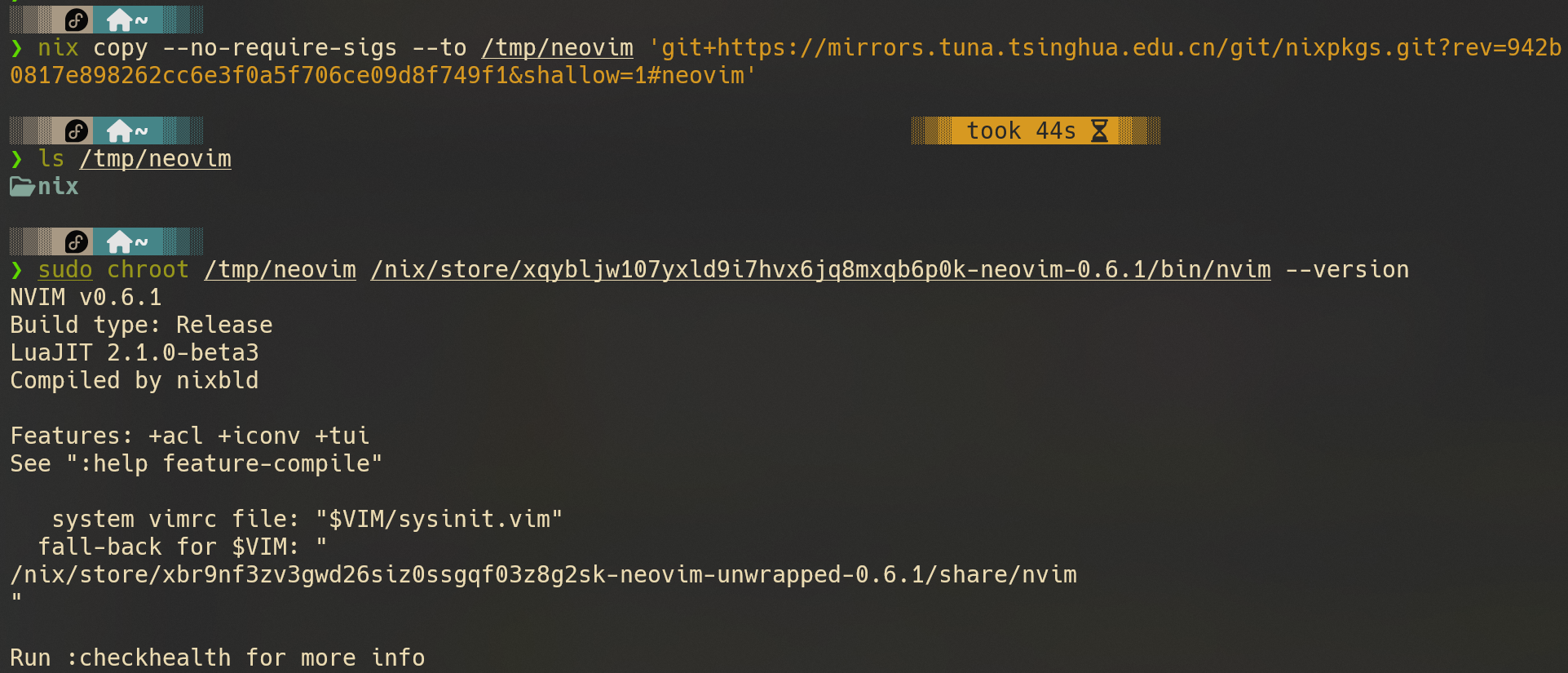
 你也可以将某个包,以及他的所有运行时依赖拷贝到别处,只需要一个内核就可以运行,可以使用chroot验证一下:
你也可以将某个包,以及他的所有运行时依赖拷贝到别处,只需要一个内核就可以运行,可以使用chroot验证一下:
 当然,nixpkgs本身也是一个flake仓库,nixpkgs仓库中任何包都可以用上面的方式操作:
当然,nixpkgs本身也是一个flake仓库,nixpkgs仓库中任何包都可以用上面的方式操作:
写在最后
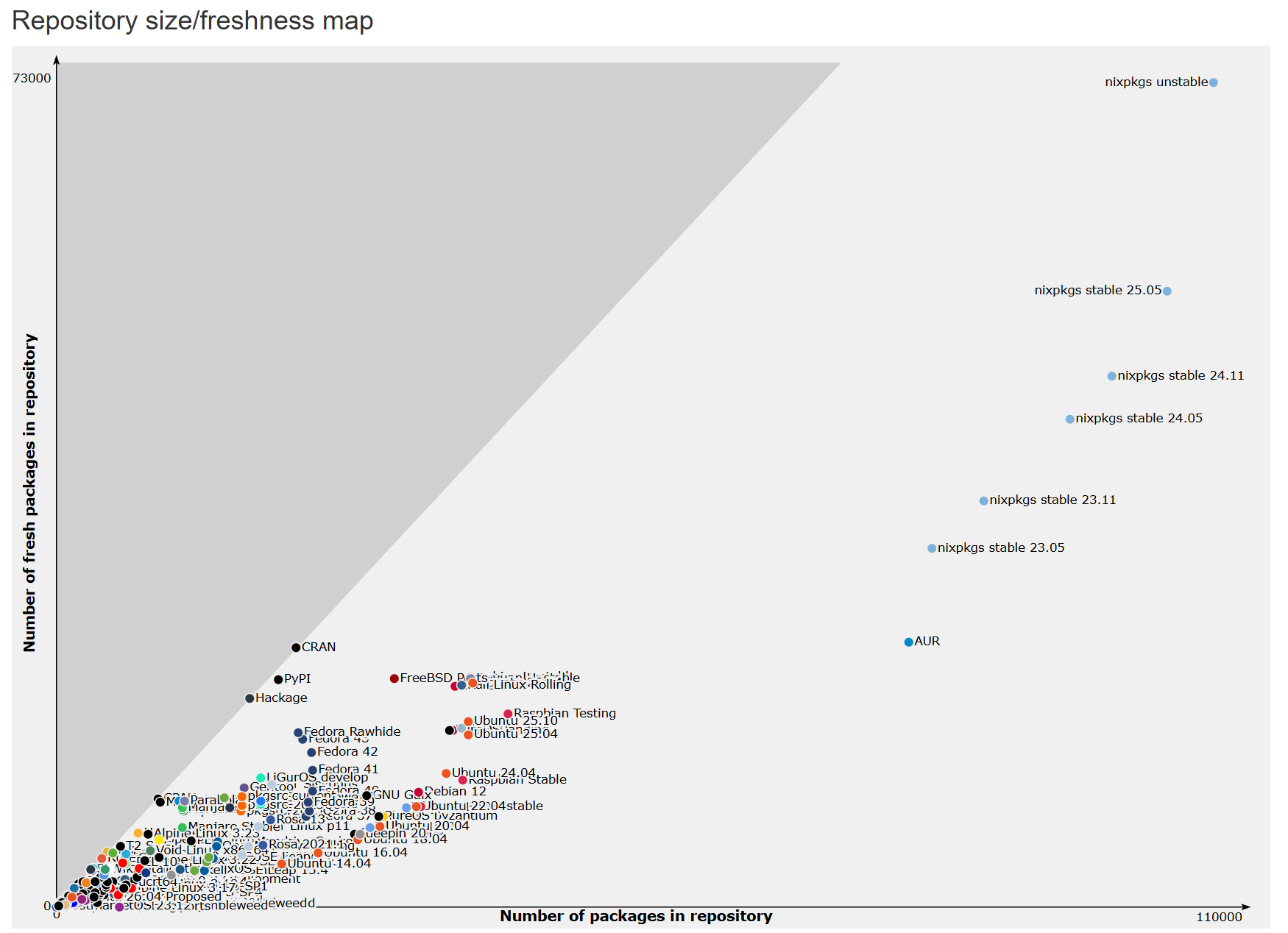
nix最令人着迷的地方之一,就是用一个非常离经叛道的方式,经过二十年的发展,造就了目前公认的维护包数量最多/最新的软件集合(repology):
 不仅如此,我认为nix很大程度从根源上解决了软件依赖的
不仅如此,我认为nix很大程度从根源上解决了软件依赖的可组合性问题,不再需要传统的发行版支撑软件构建/发布。
近两年大火的Replit,以及Google新推出的Firebase Studio,都不约而同地采用了nix作为构建其AI编程环境的核心工具:
想象一个未来,大模型只要操作nix代码,就可以构建任何东西。有一个全局唯一路径,就可以执行/构建任何程序。优秀的可复现性,无版本冲突,也许nix就是大模型时代软件基础设施的最终答案。
接下来的文章可能会介绍nixpkgs中的一些核心机制,例如evalModules、overlay,或者nixpkgs的交叉编译,又或者nixpkgs的代码结构。也许你有想要了解的nix相关话题,也欢迎私信我或在评论区留言。